Our Workflow
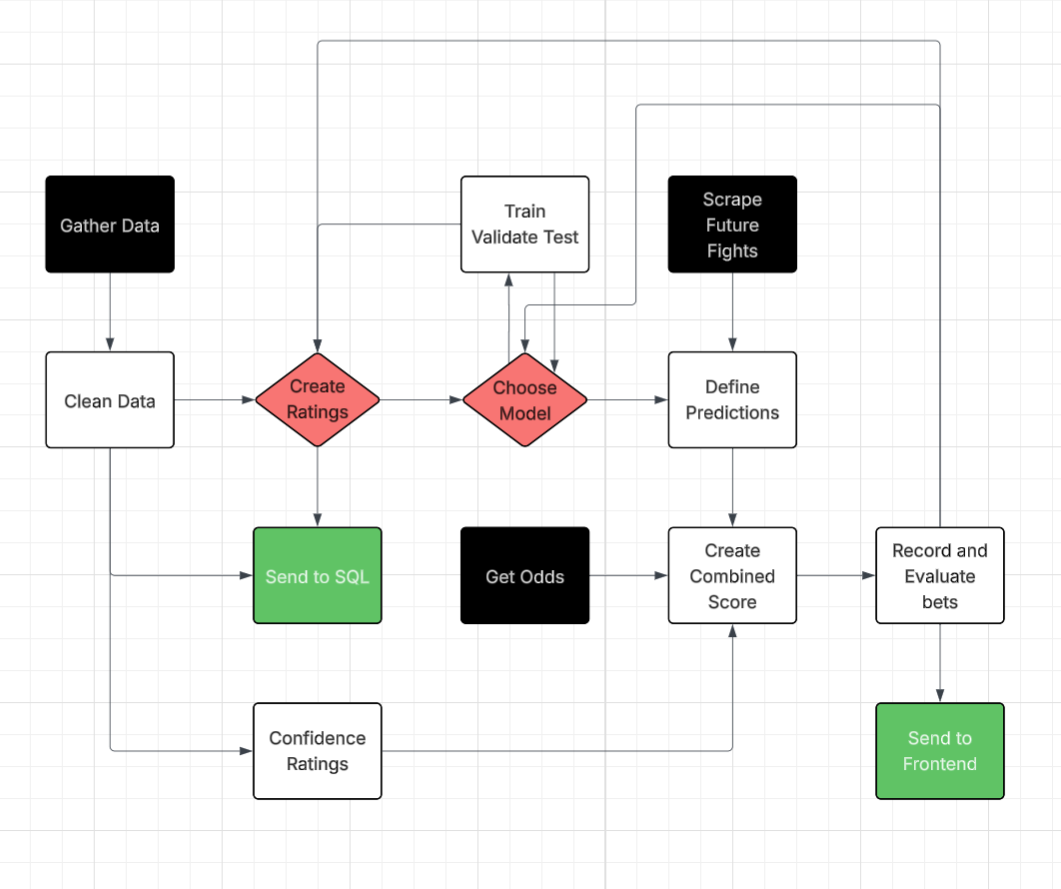
From raw UFC fight stats all the way through time-decayed ratings, model training, odds ingestion, and final picks—here’s how it all fits together.
FighterForecast is designed as a news site to help both those interested in sports betting as well as those interested in the advanced stats offered. The predictive measures are designed to maximize return on investment based on Casino odds and the model's predictive capabilities. FighterForecast also offers advanced historical ratings in a variety of statistics that amateur or seasoned MMA viewers may find value in.
Outperform both casino odds and other machine learning models by leveraging historically backed data rather than "empty" stats. FighterForecast's model only uses ratings that surround a fighter's ability to perform an action against competition well versed in preventing that action, this is the fundamental backbone behind the ratings.
Anyone from casual fans to bettors looking for a quantitative supplement to their picks.
FighterForecast was designed by a creator that aimed to beat out other machine learning models that simply take in "empty" stats such as takedown average or average significant strikes thrown per minute. These stats are considered "empty" because while they are a historical average, they do not give full context to whom those strikes or takedowns were against nor their impact on the fight's outcome.
The website and its backend were designed by I. Ramirez, for inquiries or comments email: admin@fighterforecast.com
Data Collection was made possible by the efforts of Rajeev Warrier in 2021 and his wonderful scraper available here: https://www.kaggle.com/datasets/rajeevw/ufcdata?resource=download.
Barring a few errors, the data collected is on the Ultimate Fighting Championship from 1993-Present (Only post 1998 data is used however). MMA leagues outside of the UFC bear NO WEIGHT to any aspect of the ratings nor the ability of the model to predict.
Data is freshly scraped and backend reprocessed after every UFC event.
Cleaning had to take place to remove unnecessary data, rework stats and convert the data into a format that the ratings creation files could use.
Removal of "%" based data, referee, location, fight type and other data that was unusable to create ratings.
Converted all measurements to common units, trimmed whitespace, unified naming conventions and made assumptions for incomplete data (such as when a fighter had no listed reach simply use their height.)
From the data that only contained numerical information, further trimming took place to remove stats that provided little relevance to the model. Fights pre 1998 almost always ended in the favorite or red corner winning and so they had to be removed to prevent the model from overly favoring the red corner. Other data such as where shots were landed from or submission attempts were deemed unhelpful for fight predictions. The number of attributes or features was also limited to prevent the machine learning model from struggling with too many features and too little data as only 7000 fights became relevant.
Preprocessing uses multiple different ways to squeeze as much out of sample accuracy as possible. Namely the creation of ratings, data augmentation and removal of unnecessary fights.
Ratings are generated using multiple advanced functions designed to accurately capture a fighter's ability to perform a certain action. The ratings are so powerful because they are designed to take competition into account. A high rating in body strikes for example, requires a fighter to consistently strike the body of their opponent while doing that on opponents that are generally good at preventing those strikes.
A major limitation of preforming machine learning on a process like this is the fact that their ahs only been around 8000+ UFC fights. Most ML techniques require far more data. To help the model's ability to geenralize data augmentation was performed to create an additional 6000 "mimic fights". "Mimic" Fights are created by generalizing how a fighter won, reducing their ability to perform that action, increasing an opponents ability to stop that action and then flipping who won the fight.
Classification for what an "Unecessary" fight was extensively tested to maximize accuracy. The simplest conclusion from this testing was to not attempt to predict fights of debut fighters, obvious in hindsight.
Model training proved a particular challenges due to the limitations of processing power, time and data size. To account for these factors model testing required constant reworking and backtracking.
Once ratings were created many model designs were tested. Logistic Regression, LightGBM, XGBoost, RF, Simple Neural Networks, and many other designs were tested with RF proving to be the most powerful.
Once RF was chosen fights post 2023 were treated as out of sample and odds were found to create an ROI evaluation. Models were trained on pre2023 and continuously tested with around a million different combinations of hyperparameters for the model, data augmentation and rating creation.
Many.
Once a high enough out of sample accuracy and ROC AUC was achieved. Tests on the best betting methods and other ideas from financial engineering were used.
ROI was tested using the model and attempting to discriminate certain kinds of fights. Considerations: minimum fights in the UFC, extensive underdog/favorite, low model confidence, etc.
Raw Probabilites were calibrated to adjust for what the model outputs versus the actual probability of a certain output winning.
An important part of generating the most amount of ROI was a consideration of expected return from odds and win probabilities. Top models take strategies from quantative analysts to leverage the model predictions.